From Legacy to Cloud Native: More Than Just a Lift-and-Shift
Let’s get this out of the way first: migrating to the cloud isn’t just about moving code from one place to another. If that’s all you’re doing, you’re not migrating; you’re dragging old furniture into a new house and expecting it to somehow feel modern.
This shift isn’t just technical. It’s architectural. It’s cultural. It changes how teams work, how systems evolve, and how businesses deliver value.
Here’s the trap: many teams fall into the “just keep it running” mindset. The app still loads, reports still generate, users still click. But underneath? Fragile integrations. Monolithic blobs of code. A dozen critical fixes waiting for a brave soul to touch them.
We’ve seen it happen. A logistics platform I once worked with hadn’t been touched in years. It “worked,” until one day it didn’t; and it took down half of their supply chain coordination with it. They hadn’t modernized because it never felt urgent. Until it was.
So no, this isn’t about chasing tech trends. It’s about asking: What kind of system do we want to be running two years from now; and are we willing to invest in that future today?
Understanding the Legacy Before You Let It Go
You don’t just toss your old system in the trash and walk away. Not if you want to sleep at night.
Most legacy applications aren’t just bundles of code. They’re historical artifacts. They’ve been patched, re-patched, and duct-taped together over the years. And whether it’s pretty or not, it’s probably still holding up important parts of your business.
So, before you rip anything out, map it. Understand it. Trace the weird corners and undocumented behaviors. Ask questions like:
- Which parts are still actively used?
- What dependencies exist that nobody talks about?
- What breaks if we move this without that?
Tools can help; sure. But don’t underestimate the power of just sitting down with someone who’s been around and asking, “What’s the weirdest thing this system does?”
Also: stop asking, “How fast can we move?”
Start asking, “Why are we moving in the first place?”
If you don’t have a crisp answer, stop and get one. Because that “why” will guide every painful tradeoff down the road. And believe me, there will be plenty.
Building the Right Cloud-Native Foundation, Not Just Cloud Hosting
Let me say this clearly: spinning up an AWS EC2(Amazon EC2) instance doesn’t make you cloud-native.
Cloud-native is about designing systems that scale horizontally, recover gracefully, and play well with others. It’s about containers, orchestration, and microservices; but only if those patterns actually solve your problems.
You can absolutely overengineer this. We’ve watched teams deploy Kubernetes clusters that nobody on the team knew how to troubleshoot. They didn’t need that complexity; they needed good logging and a few autoscaling rules.
What matters isn’t the tool, it’s the intent behind it. When you go cloud-native:
- Design for resilience: What happens when a service dies at 3AM?
- Design for scalability: Can you handle 10x traffic without a 10x ops team?
- Design for observability: Will your team know what’s breaking; and why; before your users do?
If you’re not building these qualities in, then you’re just renting someone else’s data center and calling it progress.
Planning Your Migration Strategy: Don’t Skip This Part
This is where too many teams stumble; they jump into migration without a game plan. Don’t.
There are real tradeoffs involved. Rehosting might be quick, but it brings your baggage with you. Refactoring gives you flexibility, but it’s time-consuming. Rebuilding from scratch? Risky unless you truly understand the business logic behind every moving piece.
You’ve probably heard of the 5 R’s:
- Rehost – Lift and shift. Minimal change, minimal reward.
- Refactor – Tweak and optimize. Useful when core functionality is solid.
- Rearchitect – Redesign to align with cloud-native principles.
- Rebuild – Start over. Do this with caution.
- Retire – Let go of what no longer adds value.
Most migrations aren’t a single R. They’re a messy blend of all five, applied to different modules, services, or workflows.
And remember; this isn’t just a tech decision. It’s a business one. You need to align your migration phases with delivery schedules, revenue-impacting deadlines, and team capacity. The best roadmap is the one your engineers can follow and your stakeholders can support.
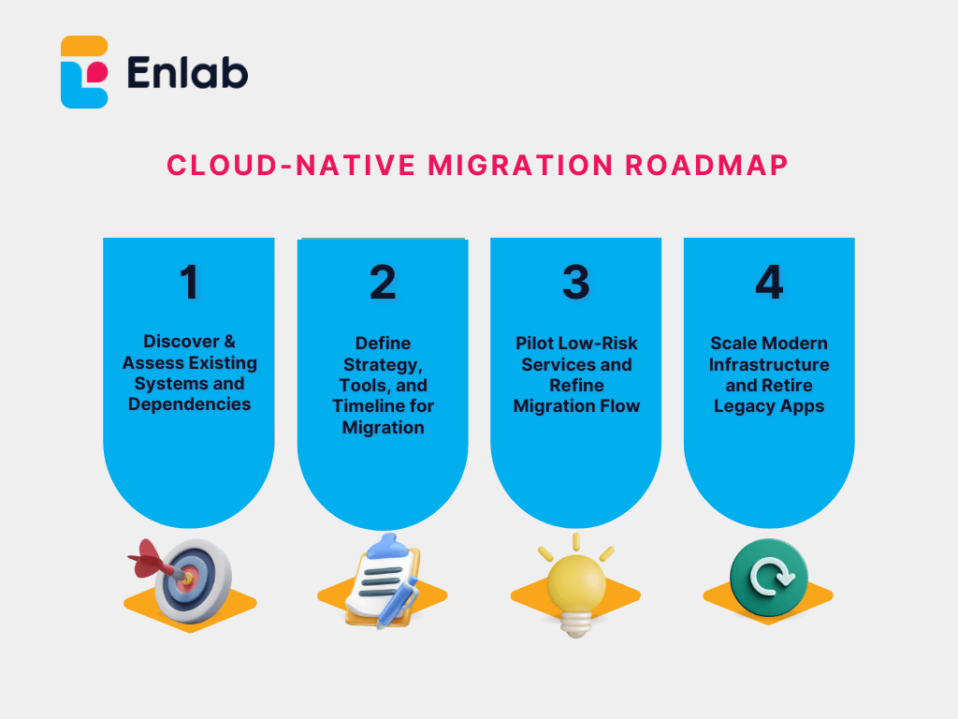
Preparing the Team: Shifting Mindsets, Not Just Skillsets
Here’s something we don’t talk about enough: migrations aren’t just hard on systems; they’re hard on people.
Think about it. You’re asking engineers to let go of the code they’ve spent years mastering. You’re asking ops folks to trust automation. You’re asking product owners to wait longer for features while the plumbing gets redone.
That’s tough. And if you ignore the human side, your migration is going to suffer.
Create space for questions. Normalize not knowing. Let teams run small experiments. Don’t just train people; include them in decision-making. When folks feel ownership, they lean in. When they feel excluded, they disengage.
Also, remember: tech changes fast. People don’t. Give your team the psychological safety they need to grow into the new environment. You’ll thank yourself later.
Executing the Migration: Start Small, Learn Fast
You don’t start a marathon with a sprint, and you don’t kick off a migration by tackling your most critical, complex module. That’s a recipe for burnout; or worse, failure.
Start where the stakes are lower. Pick a service that isn’t tied to 14 other things. Something you can move, monitor, and learn from without blowing up production. That first success? It’s not just technical; it’s emotional. It builds trust. Momentum. Proof that the plan isn’t just talk.
And here’s where automation shines; not as magic, but as muscle memory. CI/CD pipelines, infrastructure as code, automated testing; all of these make repeatability possible. But don’t let the tooling lull you into a false sense of safety. Automation catches mistakes faster, yes. But you still have to make the right calls.
One challenge teams often underestimate is how tangled legacy dependencies can be. You unplug one piece, and five others start blinking red. Plan for this. Build a compatibility layer. Use feature flags. Keep rollback options alive.
Monitoring, Measuring, and Staying Sane
Here’s the part that separates the rushed migrations from the responsible ones: how you track what’s happening after you’ve flipped the switch.
Success isn’t “it deployed.” That’s just the beginning.
You need to define what “healthy” looks like; before the migration starts. That means:
- What’s the baseline performance?
- What’s the expected error rate?
- How do you know if user experience got worse?
Then there’s observability. Not just logs, but logs you can read. Not just metrics, but alerts that fire when they should; not every 10 minutes for noise.
Modern stacks like the ELK Stack, Prometheus + Grafana, or Datadog offer fantastic visibility; but only if you feed them meaningful data. Too many teams check the “we have monitoring” box without asking: Can we tell what’s breaking? Can we see it fast enough to act?
Oh, and one more thing: your job isn’t done just because it’s in the cloud. That’s like saying you’ve won the game because you made it to the playoffs. Post-migration, your architecture needs nurturing. Tuning. Course correction. Don’t coast. You’re just getting started.
Embracing the New Normal: Life After Legacy
You’ve made it through the migration. The old system’s retired, and the new one hums along. Now what?
Here’s where many teams take a victory lap; and promptly fall into old habits.
But cloud-native isn’t a destination. It’s a way of working. That means iterating on what you’ve built, not letting it ossify. That means setting aside time to refactor, clean up technical debt, and review what’s actually working in the wild.
What’s next isn’t more tools. It’s better feedback loops. Keep talking to users. Keep listening to logs. Keep checking if the architecture still fits the business. If not? Change it. That’s the beauty of cloud-native; it lets you evolve.
And talk to other teams who’ve been through this. You’ll find shared scars and small wins. One team I spoke to spent six months breaking their monolith into services… only to realize they duplicated half their logic. That realization? It didn’t come from metrics. It came from retrospectives.
Real growth happens after the migration. That’s when teams mature; not just in skills, but in ownership.
Read More:
- Cloud Cost Optimization: Balancing Performance and Budget
- Serverless vs Containers: The Real Decision for Cloud-Native Development
- Cloud-Native Development: Building Resilient Applications
Final Thoughts: Migrating with Purpose, Not Panic
Let’s end where we began: this isn’t just about tech.
It’s about how your team approaches uncertainty. How your company embraces change. How your engineers feel empowered; or overwhelmed; by the systems they build and maintain.
Done right, a legacy to cloud native migration tells a story. It’s a statement: We’re not afraid to evolve. Not for novelty, but for resilience. For speed. For a future that doesn’t collapse under the weight of its past.
So when in doubt, zoom out. Ask why, not just how. Revisit your roadmap. Talk to your people. Because the best migrations aren’t measured in code commits or cloud spend; they’re measured in confidence, clarity, and the ability to keep moving forward.
References:
6 Strategies for Migrating Applications to the Cloud, AWS
What is Site Reliability Engineering (SRE)?, Google SRE Book
Plan, execute and monitor your cloud migration for sustained success, Dynatrace





