Without a doubt, SQL Index is one of the most important factors in the SQL Server performance tuning field. Unfortunately, few technologies cause as much confusion and misinformation as Indexes in SQL Server. This article will address the Index definition and its relevant aspects.
- People may wonder how Index improves query performance?
- Should we create Indexes on single or multiple columns?
- What is the downside of using Indexes?
Those are essential questions. But firstly, it is critical to understand the basic concept of Indexing.
What is an Index?
At first glance, it is a structure in which data is stored to verify the uniqueness or access data faster.
Why is Index essential?
Well, I am assuming that you enter a bookstore that has thousands of books. You are looking for a particular one, how can you find it?
Suppose you go through every book on shelves, which can take hours or days. It’s time for you to look at the type of book on each shelf to quickly determine where your book might be.
A similar concept is applied to a database when looking for a record from the millions of rows stored in the table. It could be the right time for you to use Index.

Source: Amazon book store
How is Index implemented in SQL Server?
A SQL Server Index is stored as a B-Tree structure which arranges 8K data pages physically in order. Just in case you do not get it yet, SQL Server stores all its data in 8K pages.
Each page in the B-Tree structure is called an index node. And there are three main levels in the B-Tree format.
- Root level: the top node that consists of a single Index page (root node).
- Leaf level: the bottom-level nodes that contain data pages of the underlying table.
- Intermediate level: one or multiple nodes between the root and the leaf level.
The root and immediate nodes contain index pages that hold index rows. Each index row contains an index key value and a pointer to the next intermediate node, or a data row in the index's leaf level.
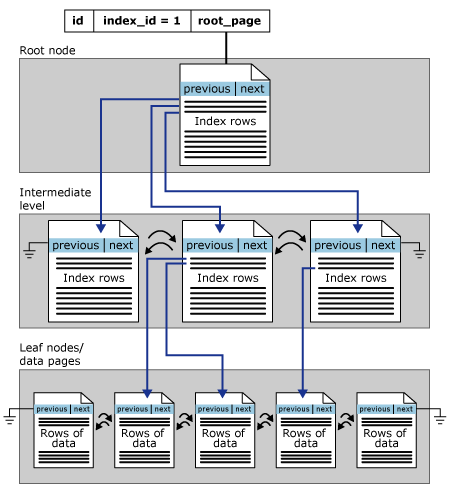
Clustered Index Structure
Assume we make an index for a table on the ID column. Then you execute a query to search for particular rows from that table. After that, the SQL Server Engine will initially navigate the root node to determine which page to reference at the top intermediate level. It then continues down through the following intermediate nodes until it can reach the target leaf node that contains the data row or pointer to that row in the underlying table.
An index can be created on single or multiple columns of the table. That is called index key(s). The index created on multiple columns is also known as the composite Index.
SQL Server Index types
There are two primary types of indexes in SQL Server, Clustered and Non-clustered Indexes. The Clustered Index stores the actual data rows of the table in the leaf node of the Index. The Non-clustered Index contains Index key columns' values with a pointer to data rows stored in the Clustered Index.
SQL Server allows only one single Clustered Index per table. And a Clustered Index is automatically created when a Primary Key constraint is defined if there is no predefined Clustered Index on the table.
There are other index types such as Unique, Filtered, and Full-text Indexes, but their specifications are enormous, so we will talk about them in other articles.
How index impacts SQL Server performance
Back to the book store's story, you have to go through all shelves in the store to search for your favorite book if the shelves are not scoped. Similarly, the SQL Server engine has to scan all data rows of a table to retrieve your request data if that table does not have an index.
Let’s take a look at the query performance with and without index. We use the AdventureWorks database in this article.
I am assuming that we execute a query to get the record in the Production.WorkOrder_NoIndex table with WorkOrderID of 56789.
SELECT * FROM [Production].[WorkOrder_NoIndex]
WHERE WorkOrderID = 56789
The Production.WorkOrder_NoIndex table does not have any index. That table is also known as a heap table in SQL Server.
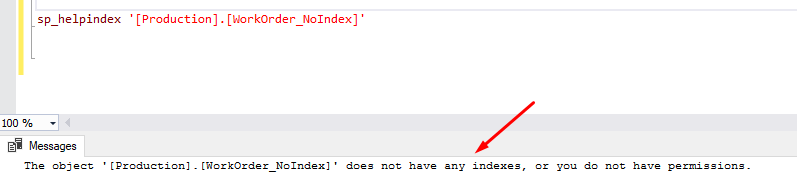
Check Index On WorkOrder NoIndex
In the query's actual execution plan, you can see that the SQL Server engine performs a ‘Table Scan’ operation to retrieve the record with WorkOrderID of 56789. It means it scans all rows in the table to get that specific record.
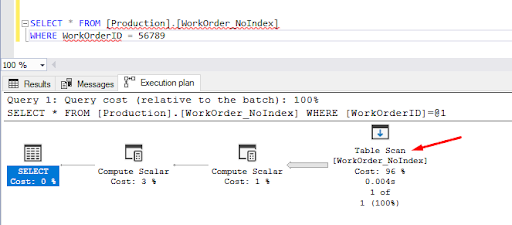
WorkOrder NoIndex Table Scan Query
Looking deeply into the operation detail, it shows that the actual result set contains only one row, but for the query execution, the engine must read all 72,591 records of that table.
- Number of Rows Read - 72,591
- Actual Number of Rows for All Executions - 1
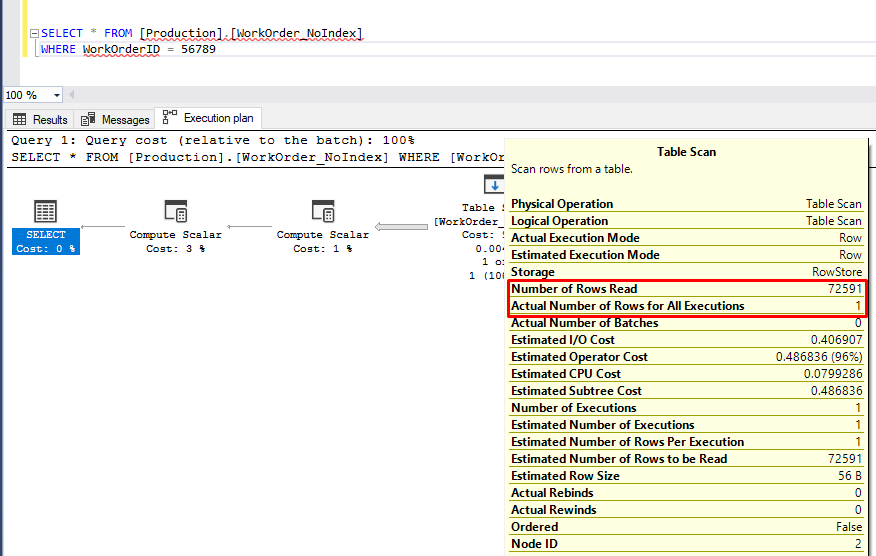
NoIndex Executed Plan
In case your tables are huge with millions of rows, it is not an effective way to traverse all rows of tables just to filter a few rows. In scale production, when your system may run hundreds of queries at a time, the resources (CPU, I/O, memory) will be exhausted. That finally leads to the performance issue.
So let’s try to run the query above on the Production.WorkOrder table with the Clustered Index on the ID column.
Check Index On WorkOrder
Instead of scanning the whole table, the engine uses a clustered index Seek operation. It “seeks” the index nodes to get the required data quickly. You can see the dramatic decrement of “Number of Rows Read” - only 1 row.
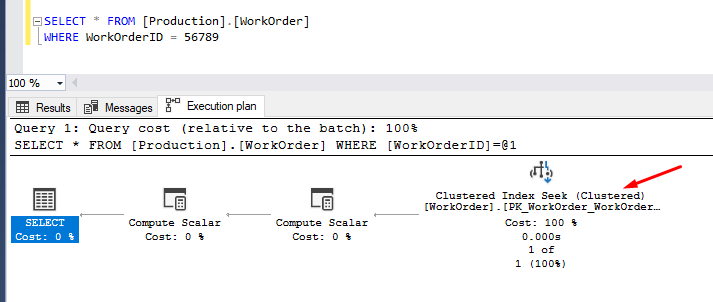
WorkOrder Index Seek Query
Also, the Estimated Operation Cost changes from 0.486836 in the first case to 0.0032831 with this execution. The query optimizer depends on this factor to choose the execution plan for queries in SQL Server.

Index Executed Plan
That is how Index improves query performance and resource utilization.
How to apply index in SQL query properly?
We already see the benefit of creating Indexes for tables in databases. But that is just one of the dozens of things we have to do to apply the index properly and get its advantage.
In some cases, SQL Server ignores using the Index seek on the desired column when executing a query. Let’s take a look at the following example.
We execute the same query in table Production.WorkOrder with a bit of modification in the Where condition
SELECT * FROM [Production].[WorkOrder]
WHERE WorkOrderID + 2 = 56789
As you can see below, SQL Server performs a Clustered Index Scan for the query, although that table already has an Index created on the ID column.

Non-Sargable Execution Plan
Because the Clustered Index stores the table’s actual data pages, Clustered Index Scan means the table scan.
Another example is the ISNULL function used on the ScrapReasonID column with a non-clustered Index of IX_WorkOrder_ScapReasonID.
SELECT * FROM [Production].[WorkOrder]
WHERE ISNULL(ScrapReasonID, 1) = 16
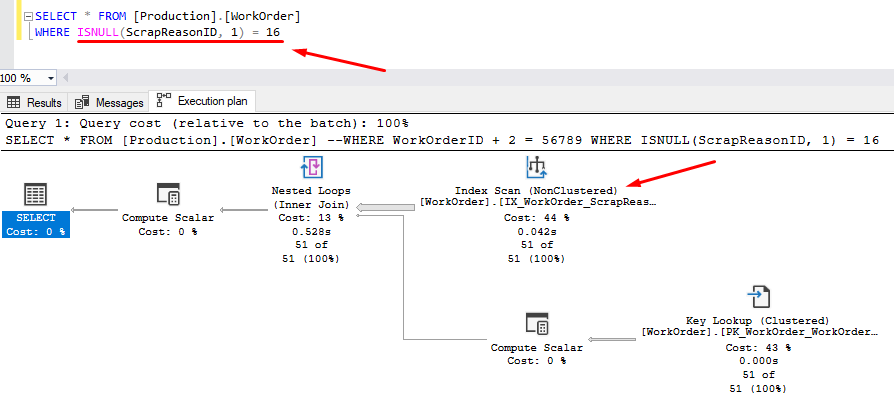
Create SQL Server Indexes
If we use a function/operation on the column included in the WHERE clause, the query becomes non-SARGable. It prevents the query optimizer from using a helpful index to speed up the query. The reason is, to apply the function/operation on a column, SQL Server has to traverse and execute the calculation for all nodes of the column index to calculate new values.
It is a wrong operation. It even costs more than the whole table scanning in a few cases so the query optimizer will use Table Scan.
So you have to understand the concept of the SARGable query. A query is SARGable, a term concatenated from Search, Argument, and Able if the engine can take advantage of the index to accelerate that query’s execution.
SQL Server Index best practices
Database index design and maintenance are some of the most important and complex tasks to developers. It includes many areas such as query optimization, index tuning, and system resource tuning, all of which need to be performed correctly to operate the scalability and high availability system.
There are no predefined principles. But there are several factors that developers should understand and consider when applying the database index.
Understanding how database design impacts index
To design a helpful index, you should understand the database’s characteristics on which the index is created. In the Online Transaction Processing (OLTP) database, many write/update operations are frequently performed along with data manipulation language queries (Insert, Update, Delete). It is recommended not to overload the database with a large number of indexes. It would be best if you created Indexes on single columns that are often selected. In other words, you should not use the composite Index if it is not essential.
Because every time the modification happens on the table, SQL Server will rearrange the index structure. This will lead to index fragmentation. Multiple columns in an index mean the server has to use more space to store it in memory. Too many indexes may have a negative impact and put stress on your system resources.
On the other hand, if the database is created to handle the Online Analytical Processing (OLAP) workload, which is often used in the Data-Warehouse as a part of the Business Intelligence system, you can add more indexes with multiple index keys.
Using indexes for the workload requirement only
Sometimes the developers create indexes blindly when creating a new table. There may be indexes that do not satisfy the query optimization. Therefore, you should carefully analyze your workload requirements and queries (including stored procedures, functions, and views) before creating an index. The key is to create the minimum number of indexes that fulfill your workload requirements.
Considering choosing the index key column
It is recommended to use an integer column in the index key. It requires a low space to store. And the column with unique and not-null column values is the best candidate for the index.
If you have to create a composite index with multiple columns, you must consider those columns' order in the Index key.
Always creating the Clustered Index before the Non-clustered one
If the table does not have any Clustered Index, the Non-clustered Index will point to row identifiers. Once you develop a Clustered Index, SQL Server will rebuild Non-clustered Indexes so that they can point to the Clustered Index key instead.
Monitoring Index maintenance frequently
You should clean up unused indexes and consolidate similar indexes frequently. Make sure your index maintenance strategy is in place. There is no point in adding more Indexes if you are not cleaning up the fragmentation and reducing splits.
Final thoughts
Using indexes is a double-edged sword. A helpful index will enhance queries and system performance without impacting the other ones. On the other hand, if you create an index without preparation or consideration, it may cause performance degradations and slow data retrieval. It also can consume more critical resources such as CPU, I/O, and memory. Additionally, indexes will increase your database maintenance tasks.
When it comes to the performance issue, you often start with the query tuning, applying the missing indexes for the table’s columns. While it may help you with that query, it may not be ideal for implementing it in your database.
Do not get me wrong, query tuning is a must, but it is just a starting point. You should do “server tuning” if you want to scale your production database.
The key is to keep these factors in mind.
- Are there other similar indexes?
- Are there any suggested missing Indexes?
Again, before you create a new index, you should check if you can consolidate the new index with an existing one and other missing index suggestions. If you can, you will get more uses out of that index. - Are there good maintenance strategies in place?
It is always better to test an appropriate index in a pre-production environment with the production equivalent workload, analyze performance and consider whether it is best to implement it on a production database.
I know this article is long. If you are still here, thank you for your patience! See you in the next blogs about indexing.

References
- Microsoft, Tables and Index Data Structures Architecture, www.docs.microsoft.com.


